유전알고리즘과 자동화계획을 이용한 게임퀘스트의 절차적 생성
2019년 10월자 컨퍼런스: 제18회 브라질 컴퓨터 게임 및 디지털 엔터테인먼트 심포지엄(SBGames 2019) 발표
- Abstract
- I. Introduction
- II. Related Work
- III. Quest Generation
- IV. Application
- V. Evaluation
- VI. Conclusion remarks
Procedural Generation of Quests for Games Using Genetic Algorithms and Automated Planning (PDF) Procedural Generation of Quests for Games Using Genetic Algorithms and Automated Planning (researchgate.net)
Abstract
개발 팀의 업무 과부하를 줄이기 위해 절차적 콘텐츠 생성 기술이 점점 더 많이 적용되고 있다. 본 논문에서는 유전 알고리즘과 자동화된 계획을 기반으로 한 새로운 퀘스트 생성 방법을 제시한다. 유전 알고리즘과 자동화 계획을 결합하면 특정 내러티브 구조를 기반으로 일관된 퀘스트를 생성해 낼 수 있다. 이 방법으로 만든 퀘스트는 게임 디자인 전문가가 만든 퀘스트와 거의 동등하다. – quest generation; genetic algorithms; planning; interactive storylling;
I. Introduction
사람이 직접 수동으로 생성하는 것이 아닌 컴퓨터에 의해 잘 정의된 절차를 실행하여 생성됩니다. 아티스트와 디자이너의 비전과 목표에 맞게 조정할 수 있습니다.
오늘날 PCG(Procedural Content Generation) 기법은 심지어 다음과 같은 일부 게임의 주요 기능 및 판매 포인트로 제시되기도 합니다. 절차적으로 생성된 오픈 월드 우주를 특징으로 하는 No Mans Sky(2016)는 고유한 에코시스템과 특질을 가진 18경 개가 넘는 행성으로 구성된 오픈 월드 세계관을 가지고 있습니다. 오늘날에는 나무, 잔디 및 기타 유형의 식생을 생성하는 데 사용되는 SpeedTree 시스템과 같은 PCG용 툴도 매우 일반적입니다. 다음과 같은 수백 개의 상업용 게임에서 식생을 생성하는 데 사용되었습니다. 호라이즌 제로 던(2017), 파 크라이 5(2018), 포르자(Forza) 호라이즌 4(2018) 등에 사용되었습니다. 그렇지만 퀘스트의 절차적 생성을 처리하는 기술은 아직 부족합니다. RPG게임은 일반적으로 퀘스트를 내러티브의 기본 매커니즘으로 사용합니다. 하지만 기존의 대부분의 내러티브 생성방법은 동적인 게임 환경에서는 동적인 게임 환경을 처리하도록 설계되지 않았습니다. 여전히 전문 라이터가 만든 수준의 복잡하고 창의적인 스토리를 제작할 수 있는 알고리즘은 아직 없습니다.
게임용 퀘스트 생성에는 여러 가지 어려움이 있습니다, 특히 플레이어, 환경, 스토리 간의 역동적인 상호 작용과 관련된 몇 가지 과제를 포함하며, 논리적 일관성을 가장 중요하게 고려해야 합니다. 사실, 비교적 중요하지 않은 사이드 퀘스트라 할지라도 같은 캐릭터가 연관된 사이드 퀘스트 혹은 게임 이벤트에 영향을 미칩니다. (예: 한 퀘스트에서 캐릭터가 사망하면, 그 캐릭터는 다음 퀘스트에서 향후 퀘스트에 살아서 등장할 수 없습니다) 퀘스트 생성 시스템의 또 다른 필수 요구사항은 다양한 플롯을 생성하는 능력에 있습니다. 게임플레이 요소의 반복은 플레이어에게 좌절감을 주는 것으로 알려져 있습니다. 따라서 적절한 수준의 다양성을 보장하는 것이 중요합니다.
이 연구에서는 퀘스트 생성 방식이 직면한 몇 가지 과제, 특히 동적인 게임 환경을 처리하고 스토리의 논리적 일관성을 보장하며 다양한 플롯을 생성하는 능력을 달성하는 방법을 목표로 합니다. 이를 위해 유전 알고리즘과 자동화된 계획에 기반한 새로운 퀘스트 생성 방법을 제안합니다. 기획과 스토리 흐름에 의해 진행되는 진화적 검색 전략과 결합함으로써 특정 내러티브 구조를 기반으로 일관된 퀘스트를 생성할 수 있습니다. 이 문서의 주요 목적은 우리의 방법을 제시하고 생성된 결과를 검증하는 것입니다. 생성된 퀘스트가 게임 디자이너가 만든 퀘스트와 얼마나 유사한지 분석하여 생성된 결과를 검증합니다.
이 문서는 다음과 같이 구성되어 있습니다. 섹션 II에서는 관련 작업을 설명합니다. 섹션 III에서는 제안된 퀘스트 생성 방법을 소개하고 유전 알고리즘의 구현 세부 사항을 설명합니다. 섹션 IV에서는 게임 프로토타입에 이 방법을 적용한 사례를 설명합니다. 섹션 V에서는 방법의 평가를 제시합니다. 섹션 VII에서는 결론 비고를 제공합니다.
II. Related Work
Sullivan(A. Sullivan, M. Mateas, and N. Wardrip-Fruin, “Rules of engagement: Moving beyond combat-based quests,” Proceedings of the Intelligent Narrative Technologies III Workshop (INT3 ‘10), Article No. 11, ACM, 2010, doi: 10.1145/1822309.1822320.)
- 게임 매니저가 플레이어 히스토리와 월드의 현재 상태를 사용하여 퀘스트 구조를 동적으로 생성하고 재조합
Breault(V. Breault, S. Ouellet, and J. Davies, “Let CONAN tell you a story: Procedural quest generation,” arXiv:1808.06217, 2018.)
- 자동화된 계획에만 의존하여 퀘스트를 생성
- 집합으로 표현된 세계 설명을 받아서 결정론적 계획 알고리즘을 사용하여 세계 상태에 따라 퀘스트를 생성
Lima(S. Lima, B. Feijó, and A. L. Furtado, “Hierarchical Generation of Dynamic and Nondeterministic Quests in Games,” Proceedings of the 11th International Conference on Advances in Computer Entertainment Technology, ACM, 2014, Article N. 24, doi: 10.1145/2663806.2663833.)
- 보다 동적인 솔루션
- 비결정론 하에서 계층적 작업 분해 및 계획을 기반으로 퀘스트를 생성하는 방법
- 계획, 실행, 모니터링을 결합하여 비결정적 이벤트를 처리
- 게임 내러티브에 영향을 미치는 여러 엔딩이 있는 퀘스트를 지원하며 상호작용적이고 동적인 스토리 플롯을 생성
우리가 아는 한, 퀘스트 생성에 유전 알고리즘을 직접적으로 사용한 선행 연구는 없지만 일반적인 내러티브 생성에 유전 알고리즘을 사용한 몇 가지 관련 연구를 찾을 수 있었습니다.
McIntyre와 Lapata(N. McIntyre, and M. Lapata, “Plot induction and evolutionary search for story generation,” Proceedings of the 48th Annual Meeting of theAssociation for ComputationalLinguistics, 2010,pp.1562–1572)
- 각 플롯이 (내러티브 텍스트의 문장에 해당하는) 의존성 트리의 정렬된 그래프로 표현
- 진화적 검색 전략을 사용하는 스토리 생성기 시스템
- 알고리즘이 텍스트 문장에서 직접 작동하기 때문에 유전 연산은 문장의 모든 동사, 명사, 부사, 형용사에서 발생할 수 있는 변이와 같은 문장의 구문과 의미를 처리하도록 설계
- 명사, 부사 또는 형용사가 돌연변이를 거치도록 선택되면 충분히 유사한 새로운 어휘 항목으로 대체
- 일관성에 따라 후보에 점수를 매기는 적합도 함수를 사용
Ong과 Leggett(T. Ong, and J. J. Leggett, “A genetic algorithm approach to interactive narrative generation,” Proceedings of the fifteenth ACM conference on Hypertext and hypermedia, 2004, pp. 181–182)
- 유전 알고리즘을 사용
- 스토리 템플릿 세트에서 생성된 스토리 구성 요소를 재조합하여 내러티브 생성
- 스토리 작성자가 사전에 평가한 이벤트에 의해 스토리 적합성이 결정됨
- 기본 구조는 미리 결정된 템플릿에 설명된 규칙과 조건에 의해 보장됨
S. Giannatos, M. J. Nelson, Y.-G. Cheong, and G. N. Yannakakis, “Suggesting new plot elements for an interactive story,” Proceedings of the Workshop on Intelligent Narrative Technologies, Artificial Intelligence and Interactive Digital Entertainment Conference (AIIDE 2011), AAAI, 2011, pp. 25–30.
- 진화 알고리즘을 사용하여 기존 스토리 그래프에 추가하면 스토리 공간의 횡단 품질을 개선할 수 있는 새로운 스토리 이벤트를 제안하는 시스템
- 후보 플롯 포인트로 스토리 그래프를 구성한 후, 그 스토리에서 가능한 100개의 플레이를 샘플링함. 그런 다음 샘플링된 스토리를 공간적 위치, 생각의 흐름, 동기의 세 가지 기준에 따라 평가.
- 최종 적합도는 모든 플레이를 평가하여 얻은 적합도 값의 평균으로 계산됩니다.
M. Nairat, P. Dahlstedt, and M. G. Nordahl, “Character evolution approach to generative storytelling,” Proceedings of the 2011 IEEE Congress of Evolutionary Computation, 2011, pp. 1258–1263. M. Nairat, P. Dahlstedt, and M. G. Nordahl, “Story Characterization Using Interactive Evolution in a Multi-Agent System, ” In: P. Machado, J. McDermott, and A. Carballal (eds), Evolutionary and Biologically Inspired Music, Sound, Art and Design, Springer, 2013.
- 플롯 기반 접근 방식을 따르는 대신 캐릭터 기반 시스템에 진화적 방법을 통합하는 다른 접근 방식.
- 대화형 유전 알고리즘을 사용
- 캐릭터를 생성하는 에이전트 기반 시스템을 통합하는 스토리 생성 방법
- 이 방법에서 에이전트 각각은 성격과 행동을 정의하는 내부 상태(자원 및 감정)와 행동 규칙으로 표현됩니다.
- 작성자는 의도한 스토리와 관련된 행동을 하는 에이전트를 관찰하고 선택.
- 작성자가 캐릭터가 더 발전시킬 수 있을 만큼 흥미롭다고 판단하면 시스템은 재생산 프로세스를 수행하여 새로운 세대를 생성
S. Giannatos, Y.-G. Cheong, M. J. Nelson, and G. N. Yannakakis, “Generating Narrative Action Schematics for Suspense,” Proceedings of the Workshop on Intelligent Narrative Technologies, Artificial Intelligence and Interactive Digital Entertainment Conference (AIIDE 2012), AAAI, 2012, pp. 8–13
- 유전 알고리즘과 계획 알고리즘의 조합
- 유전 알고리즘을 사용하여 가능한 스토리 액션을 나타내는 계획 연산자를 생성
- 관계심볼과 액션 연산자(사전 조건과 사후 조건으로 정의)를 사용하여 스토리를 표현
- 유전 알고리즘의 목표는 새로운 스토리 플롯을 구성하기 위한 내러티브 단위로서 계획 연산자를 생성하는 것
- 솔루션을 평가하기 위해서는 연산자가 긴장감 있는 스토리를 생성하는 데 기여한 정도를 추정
- 초기상태와 목표를 변경하지 않고 새로운 연산자(매개변수, 전제조건, 효과)를 생성하는 데만 유전 알고리즘을 사용
- 연산자가 어떤 종류의 액션/이벤트를 나타내는지는 명시하지 않는다.
이처럼… 퀘스트 및 내러티브 생성은 게임 및 비게임 분야에서 학계 연구자들에 의해 광범위하게 연구되어 왔지만, 대부분의 방법은 기존 퀘스트 라이브러리나 미리 정의된 목표 상태를 가진 계획 문제에 대한 매우 상세한 설명이 필요하므로 추가적인 저작 작업이 요구되고 가능한 퀘스트의 공간을 제한합니다. 이러한 맥락에서 유전 알고리즘의 사용은 이벤트 구조가 필요하지 않거나 다른 방법으로 실제 내러티브 생성을 담당하는 비게임 애플리케이션으로 제한되어 왔습니다.
III. Quest Generation
게임에서 ‘퀘스트’에 대한 명확한 이론은 존재하지 않습니다. 내러티브에 대한 개념이 정확하게 정의되지 않았기 때문입니다. 이 논문에서는 ‘퀘스트’란 플레이어가 수행해야 하는 일련의 작업이라고 정의합니다. 플레이어가 수행해야하는 일련의 작업 세트는 퀘스트의 스토리가 됩니다. 각 퀘스트에는 고유한 줄거리를 가지고 있지만 모든 퀘스트는 같은 월드에서 진행되므로 월드 상태의 변화가 향후 퀘스트의 플롯에 영향을 미칠 수 있습니다. 게임 세계에는 수천 개의 사물, 아이템, 적, 장소가 존재하며, 수십 명의 비플레이어 캐릭터, 그리고 장소가 존재합니다. 또한 플레이어는 세계와 상호작용할 수 있습니다. 플레이어는 수십 가지의 다양한 행동을 수행함으로써 세계와 상호작용할 수 있습니다. 따라서 “좋은” 작업 순서를 찾는 것이 더 복잡해집니다. 이러한 유형의 문제에서 검색 공간은 일반적으로 수천 개의 노드를 포함하며 수만 개의 가능한 퀘스트를 생성할 수 있습니다. 이러한 맥락에서 유전 알고리즘은 더 효율적인 검색과 탐색이 가능하기 때문에 유리합니다.
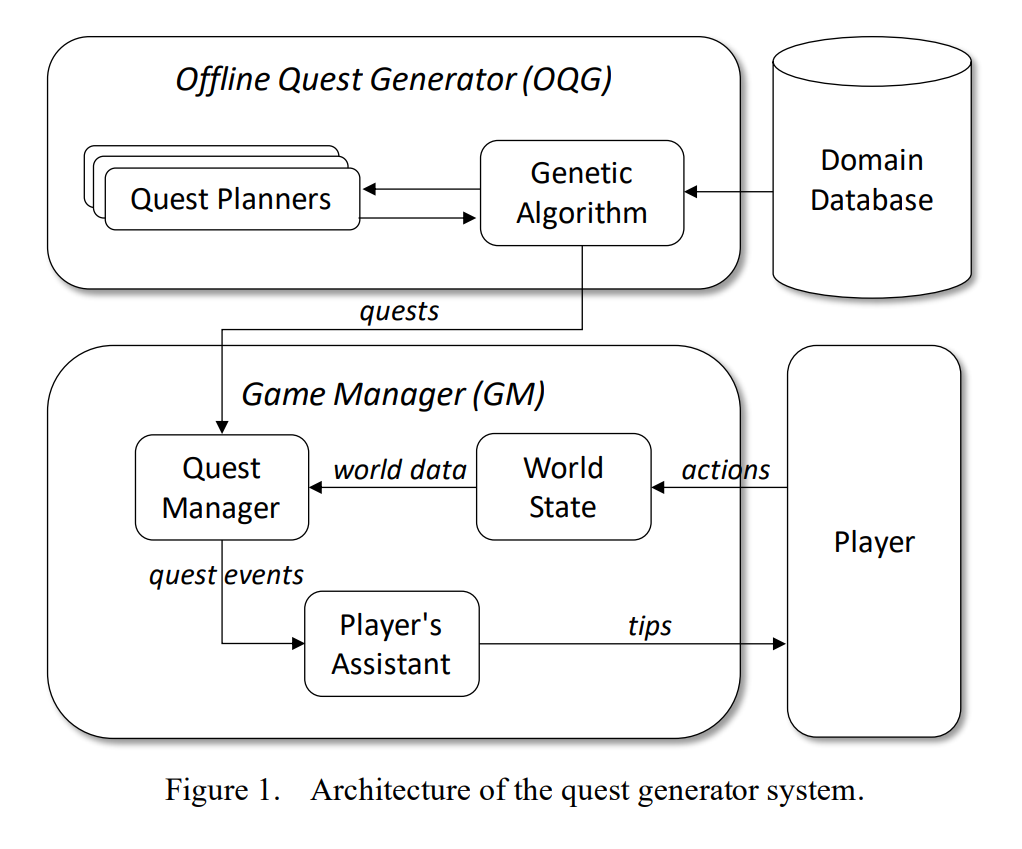
그림 1과 같이 제안한 퀘스트 생성기 시스템의 아키텍처는 (1) 유전 알고리즘을 실행하고 결과(생성된 퀘스트)를 처리하는 오프라인 퀘스트 생성기(OQG)와 (2) 플레이어가 실시간으로 상호작용하는 동안 퀘스트 실행을 처리하는 게임 관리자(GM) 두 가지 하위 시스템으로 구성됩니다.
OQG는 전처리 단계(오프라인)에서 실행되며 게임에 대해 생성된 전체 퀘스트 세트를 GM에게 제공합니다. OQG의 일부인 유전 알고리즘 모듈은 기존 유전 알고리즘의 모든 방법을 구현하고 퀘스트 플래너의 실행을 처리하여 생성된 퀘스트의 유효성을 검사합니다. 퀘스트는 유효한 이벤트, 캐릭터, 장소, 게임 세계의 일부인 오브젝트의 정의가 포함된 도메인 데이터베이스에 저장된 정보를 기반으로 생성됩니다. 플레이어가 게임과 상호작용하는 동안 플레이어의 행동은 월드 상태를 업데이트하는 데 사용되며, 퀘스트 관리자는 퀘스트 수행 시 플레이어의 진행 상황을 추적하는 데 차례로 사용됩니다. 한편, 플레이어는 현재 퀘스트의 다음 목표에 대한 팁을 제공하는 플레이어 도우미의 도움을 받습니다.
A. Genetic Algorithm
진화 이론에 따르면, 생태계에서는 언제든지 여러 가지 다른 유기체가 공존하며 동일한 자원을 놓고 경쟁할 수 있습니다. 자원을 획득하고 성공적으로 번식하는 능력이 더 뛰어난 유기체는 미래에 더 많은 후손을 낳을 것입니다. 능력이 떨어지는 유기체는 후손이 거의 없거나 전혀 없는 경향이 있습니다(생존 확률이 낮아집니다). 시간이 지남에 따라 생태계의 전체 개체군은 이전 세대보다 환경에 더 적합하고 적응력이 뛰어난 유기체를 포함하도록 진화할 것입니다(적자생존이 촉진됨).
유전 알고리즘은 이러한 진화 이론을 계산 프로세스로 추상화한 것입니다. 전통적인 구현에서는 초기 개체군(염색체라고도 함)가 무작위로 생성되며, 이 구조는 일반적으로 고정 길이의 비트 문자열로 정의됩니다. 문자열의 각 위치는 개체의 특징이 됩니다. (유전자에 비유하자면 생물학적 유기체의 DNA). 모집단의 각 개체는 적합도가 평가되고, 그 점수에 따라 선택됩니다. 선택되고 크로스오버(재생산 또는 재조합) 및 돌연변이 과정을 거쳐서 새롭고 진화한 개체군은 일반적으로 우수한 개체의 유전자를 결합하기 때문에 일반적으로 부모보다 우수합니다. 따라서 자손은 이전 세대의 열등한 개체를 대체하기 위한 새로운 집단으로 편성됩니다. 이 과정은 주어진 종료 기준이 트리거될 때까지(일반적으로 n단계의 세대) 진화로 이어집니다.

그림 2에서 볼 수 있듯이, 우리의 방법은 기존 유전 알고리즘의 주요 단계를 포함합니다. 기존 유전 알고리즘의 주요 단계(모집단 초기화, 평가, 선택, 크로스오버, 돌연변이)와 함께 추가 제어 루프를 추가하여 순차적 퀘스트의 제어 루프가 추가되었습니다. 도메인 데이터베이스에 저장된 월드 상태를 업데이트하여 이전에 생성된 퀘스트의 최종 상태에서 추출된 정보로 월드 상태를 업데이트하여 알고리즘은 논리적 일관성을 보장할 수 있습니다.
유전 알고리즘에서 각 개체(즉, 각 염색체)는 퀘스트를 나타내며, 이는 플래닝(계획) 문제로 인코딩됩니다.  여기서 𝑃는 원자 공식(또는 줄여서 원자)의 집합, 𝑂는 계획 연산자 집합, 𝑆0은 퀘스트의 초기 상태, 𝐺는 목표 상태입니다: 즉 퀘스트 = (원자집합, 퀘스트초기상태, 목표상태, 계획연산자집합)
여기서 𝑃는 원자 공식(또는 줄여서 원자)의 집합, 𝑂는 계획 연산자 집합, 𝑆0은 퀘스트의 초기 상태, 𝐺는 목표 상태입니다: 즉 퀘스트 = (원자집합, 퀘스트초기상태, 목표상태, 계획연산자집합)
- 원자는 𝑝𝑟𝑒𝑑(𝑟1 , ⋯ , 𝑟𝑘) 형식의 표현식으로, 여기서 pred는 (dredicate symbol)관계 심볼이고 𝑟1, ⋯ , 𝑟𝑘는 변수 용어(예: CH1, IT) 또는 접지 용어(예: player, antidote)입니다
- 리터럴은 원자 𝑝 또는 원자의 부정인 ¬𝑝이며, 부정은 현재 세계 상태 S에서 명제를 삭제하는 것을 나타냅니다(즉, 폐쇄 세계 가정을 사용합니다: 상태에 명시적으로 지정되지 않은 명제는 해당 상태에서 유지되지 않습니다).
- 𝑆0 ⊆ 𝑃와 𝐺 ⊆ 𝑃는 그라운드 리터럴의 집합입니다. 연산자 𝑜 ∈ 𝑂는 다음과 같이 표시됩니다.

- 𝑛𝑎𝑚𝑒(𝑜)는 원자 𝑜𝑝(𝑥1, 𝑥2, … , 𝑥𝑘)인 연산자의 이름으로, 여기서 𝑜𝑝는 연산자 기호라는 고유 기호이고 𝑥𝑖는 o의 어느 곳에서나 발생하는 가변 기호입니다;
- 𝑝𝑟𝑒𝑐𝑜𝑛𝑑(𝑜)는 𝑜의 전제 조건을 정의하는 리터럴 집합(즉, 연산자 𝑜를 사용하기 위해 참이어야 하는 양수 및/또는 음수 리터럴)입니다.
- 𝑒𝑓𝑓𝑓𝑒𝑐𝑡(𝑜)는 𝑜의 효과를 정의하는 리터럴 집합(즉, 연산자 𝑜가 보유하게 될 양수 및/또는 음수 리터럴)입니다.
개체의 유전 구조는 도식적 요소와 반응적 요소로 구성됩니다. 𝑃과 𝑂는 모두 도식적이며 도메인(게임 세계)의 개념적 스키마의 일부로 정의됩니다. 𝑂는 퀘스트 진행 중에 발생할 수 있는 이벤트 유형을 정의하는 반면, 𝑃는 상태, 목표 및 연산자를 설명하는 데 사용할 유효한 원자를 설정합니다. 이러한 도메인 요소는 도식화되어 있으며 모든 개인의 계획 문제를 구성하는 데 사용됩니다.
반면 𝑆0과 𝐺(초기 상태와 목표 상태)는 반응적이며 개인마다 다를 수 있으며, 성격에 따른 선호도에 따라 상황을 인식하는 방식과 상황을 바꾸려는 충동을 다르게 표현합니다. 따라서 𝑆0과 𝐺는 각 개인의 특징을 정의하는 요소이며, 결과적으로 크로스오버와 돌연변이 연산에 적용되는 요소입니다. 이러한 요소는 고정된 길이가 없는 Ground Literal의 집합이라는 점을 고려할 때, 개체의 유전적 구조에서 두 개의 연결된 목록으로 표현됩니다(고정 길이 비트스트링을 사용하는 기존의 구현과는 대조적으로).
다음 예는 유전 알고리즘에서 개체를 표현하는 방법을 보여줍니다(단순화를 위해 이 예와 관련이 없는 연산자와 원자는 생략했습니다):
Schematic:
P: at(C, P), has(C, P), hero(C), healthy(C),
isantidote(I), alive(C), infected(C), cured(C), path(L1, L2)
o1:
name: go(CH, PL1, PL2)
precond: character(CH), place(PL1), place(PL2),
at(CH, PL1), alive(CH), hero(CH), path(PL1, PL2)
effect: at(CH, PL2), ¬at(CH, PL1)
o2:
name: get(CH, IT, PL)
precond: character(CH), item(IT), place(PL),
at(CH, PL), alive(CH), hero(CH), at(IT, PL)
effect: has(CH, IT), ¬at(IT, PL)
o3:
name: attack(ZO, CH, PL)
precond: zombie(ZO), character(CH), place(PL),
at(CH, PL), at(ZO, PL), alive(CH), healthy(CH)
effect: infected(CH), ¬healthy(CH)
o4:
name: cure(CH1, CH1, IT, PL)
precond: character(CH1), character(CH3), item(IT),
place(PL), at(CH1, PL), at(CH2,PL), alive(CH1),
hero(CH1) alive(CH2), infected(CH2),
has(CH1, IT), isantidote(IT)
effect: cured(CH2), healthy(CH2), ¬infected(CH2), ¬has(CH1, IT)
Reactive (S0 with 20 genes and G with 4):
S0: character(john), character(anne), place(village), place(johnhome),
place(store), item(antidote1), isantidote(antidote1), hero(john),
alive(john), alive(anne), healthy(john), healthy(anne),
enemy(zombie), path(johnhome, village), path(village, johnhome),
path(store, village), path(village, store), at(john, johnhome),
at(anne, johnhome),at(antidote1, store)
G: cured(anne), healthy(anne), at(john, johnhome), alive(john)
위의 예에서 도식 요소는 문제를 설명하는 데 사용되는 원자 어휘(𝑃)와 퀘스트에서 가능한 이벤트를 나타내는 잘 알려진 STRIPS(Stanford Research Institute Problem Solver) 형식주의에 기반한 네 가지 연산자(이동, 획득, 공격, 치료)를 포함하는 계획 문제의 도메인을 정의합니다.
*STRIPS란… STRIPS는 문제를 일련의 작은 하위 문제로 세분화하는 방식으로 작동하는 계획 알고리즘입니다. 그런 다음 휴리스틱 검색 알고리즘을 사용하여 각 하위 문제에 대한 해결책을 찾습니다. 그런 다음 하위 문제에 대한 솔루션에서 최종 솔루션을 조합합니다. STRIPS는 계획 및 스케줄링 문제, 리소스 할당 문제, 경로 찾기 문제 등 AI의 다양한 문제를 해결하는 데 사용되어 왔습니다.
퀘스트의 초기 상태(𝑆0)를 보면 알다시피 john과 anne이 캐릭터임을 정의하며, john은 스토리의 주인공입니다. johnhome, village, store는 장소이고, 존과 앤은 모두 존홈에 있으며, 살아 있고 건강하고, 해독제1는 상점에 있는 아이템이고, 적인 좀비가 있고, 존홈과 마을을 연결하는 경로(장소를 연결하는 다른 경로 중 하나)가 있습니다. 목표 상태(𝐺)는 앤이 치료되고 건강해야 하며, 존은 살아서 존홈에 있어야 한다는 것입니다.
플래너가 개인의 계획 문제를 해결할 때 퀘스트의 플롯은 플레이어가 수행해야 할 이벤트 또는 작업의 선형적인 시퀀스로 설정됩니다. 위의 예에서 플롯은 다음과 같이 구성됩니다:
attack(zombie, anne, johnhome), go(john, johnhome, village), go(john, village, store), get(john, antidote1, store), go(john, store, village), go(john, village, johnhome), cure(john, anne, antidote1, johnhome).
유전 알고리즘의 초기 모집단의 개체는 도메인 데이터베이스(𝐷𝐵)에 정의된 정보에 따라 무작위로 생성되며, 이는 집합인 3입니다: 
- Α
- 게임 월드(𝑜𝑏𝑗 𝑖)의 모든 객체를 정의하고 특정 객체 유형(𝑜𝑏𝑗 𝑇y𝑝𝑒 𝑖)과 연관시키는 𝛼𝑖 = (𝑜𝑏𝑗 𝑖, 𝑜𝑏𝑗 𝑇y𝑝𝑒 𝑖) 쌍의 집합입니다.
- 예를 들어 Α= {(john, 캐릭터), (home(john), 장소), (antidote1, 아이템)}은 john은 캐릭터, home(john)은 장소, antidote1은 아이템임을 정의합니다. 현재는 단순화를 위해 함수 기호를 상수로 표현합니다(예: home(john) 대신 johnhome 사용);
- Β
- 게임 월드에 존재하는 객체의 속성과 관계를 설명하는 리터럴 집합입니다(예: Β = {경로(존홈, 마을), 살아있음(존), at(존, 존홈), isantidote(해독제1)});
- Γ
- 𝑝𝑟𝑒𝑑 𝑖에 대한 의미 무결성 제약 조건의 집합으로, 알고리즘의 염색체 생성 과정에서 핵심적인 역할을 합니다.
- 현재 저희는 변수 유형, 모순 또는 반대 관계, 실존적 유일성 정량화라는 세 가지 제약 조건을 가지고 있습니다. 즉, 집합 Γ의 각 멤버는 𝛾𝑖 = (𝑝𝑟𝑒𝑑 𝑖, 𝑜𝑝𝑝 𝑖, (𝑢1𝑡1, ⋯ , 𝑢𝑛𝑡𝑛))입니다.
- 여기서 𝑝𝑟𝑒𝑑 𝑖는 n 개의 항을 가진 술어 기호입니다(예 at, has, cured),
- 𝑜𝑝𝑝 𝑖는 𝑝𝑟𝑒𝑑 𝑖의 반대 술어입니다,
- 𝑡 𝑗은 𝑝𝑟𝑒𝑑 𝑖 의 𝑗 번째 접두사가 술어의 유효한 인스턴스를 생성하는 데 필요한 객체 유형(𝑜𝑏𝑗𝑇y𝑝𝑒)을 나타내고,
- 𝑢𝑗은 고유성 정량화 ∃를 나타냅니다. 𝑡𝑗 𝑝𝑟𝑒𝑑𝑖 (즉, 𝑝𝑟𝑒𝑑𝑖가 참인 𝑡𝑗가 정확히 하나만 존재합니다).
- 예를 들어 𝛾𝑖 = (𝑐𝑢𝑟𝑒𝑑, (𝑐ℎ𝑎𝑟𝑎𝑐𝑡𝑒𝑟))는 술어 cured에 반드시 타입 문자인 단일 항이 있음을 나타냅니다. 반대 관계의 예는 𝛾𝑖 = (ℎ𝑒𝑎𝑙𝑡ℎ ,𝑖𝑛𝑓𝑒𝑐𝑡𝑒𝑑, (𝑐ℎ𝑎𝑟𝑎𝑐𝑡𝑒𝑟))로, 건강한(존) 또는 감염된(존) 중 하나만 보유하지만 둘 다 보유하지 않음을 나타냅니다.
- 용어의 고유성의 예로는 𝛾𝑖 = (𝑎𝑡, (𝑐ℎ𝑎𝑟𝑎𝑐𝑡𝑒𝑟, ∃! 𝑝𝑙𝑎𝑐𝑒))로, 각 문자가 한 번에 한 곳에만 존재할 수 있음을 나타냅니다. 이 후자의 경우 술어 at(john,…)는 문자 john에 대해 한 상태에서 한 번만 나타날 수 있습니다;
- Δ
- 퀘스트 진행 중에 발생할 수 있는 모든 가능한 이벤트를 나타내는 STRIPS 형식주의(전제 조건 및 효과 포함)에 기반한 계획 연산자 집합을 정의합니다.
- Ε
- 𝜀𝑖 = (𝑜𝑖,𝑡𝑒𝑛 𝑖𝑜𝑛𝑖) 쌍의 집합으로, 각 연산자 𝑜𝑖가 퀘스트의 전체 텐션(𝑡𝑒𝑛s𝑖𝑜𝑛 𝑖)에 영향을 미치는 방식을 설정하며, 이는 증가(+), 감소(-) 또는 유지(=)할 수 있습니다. 예를 들어 공격 연산자는 긴장감을 조성하고 치료는 긴장감을 감소시키는 해결책을 나타내므로 Ε= {(공격, +), (치료, -), …}가 됩니다.
유전 알고리즘을 위한 초기 모집단을 생성하기 위해 모집단의 개체를 나타내는 계획 문제가 생성됩니다. 각 계획 문제의 도식 요소의 경우 𝑃는 Α ⊆ 𝐷𝐵 및 Β ⊆ 𝐷𝐵에 있는 고유 원자로 정의되며, 𝑂는 Δ ⊆ 𝐷𝐵에 정의된 계획 연산자로 생성됩니다. 반응 요소의 경우, 먼저 퀘스트의 초기 상태(𝑆0)가 게임 세계의 도식 요소(Α ⊆ 𝐷𝐵)로 초기화된 다음, Γ ⊆ 𝐷𝐵에서 설정된 의미 무결성 제약 조건에 따라 다수의 새로운 Ground literal(변수 없이 특정한 값이나 상수로만 이루어진 리터럴)이 임의로 생성되어 𝑆0에 추가됩니다.
마찬가지로, 목표 상태(𝐺)에 대해 임의의 수의 Ground Literal이 생성됩니다. 무작위 Ground Literal을 생성하는 프로세스는 동일한 상태에 반복되는 Ground Literal을 추가하는 것을 자동으로 방지하고, 한 상태에서 한 번만 나타나야 하는 특정 용어(Γ ⊆ 𝐷𝐵에 따라)가 포함된 리터럴의 고유성을 보장합니다. 모집단의 개체 수와 𝑆0 및 𝐺에 추가될 총 Ground Literal 수는 유전 알고리즘의 파라미터를 통해 정의됩니다.
마찬가지로, 목표 상태(𝐺)에 대해 임의의 수의 Ground Literal이 생성됩니다. 무작위 ground literals을 생성하는 프로세스는 동일한 상태에 반복되는 ground literals을 추가하는 것을 자동으로 방지하고 한 상태에서 한 번만 나타나야 하는 특정 용어(Γ ⊆ 𝐷𝐵에 따라)가 포함된 리터럴의 고유성을 보장합니다. 모집단의 개체 수와 𝑆0 및 𝐺에 추가될 총 Ground Literal수는 유전 알고리즘의 파라미터를 통해 정의됩니다.
실험에서는 100명의 모집단과 1~30 범위의 임의 값을 사용하여 𝑆0의 Ground Literal 수와 𝐺의 1~10을 정의합니다.
초기 모집단을 생성한 후, 각각은 플롯의 스토리 아크에 따라 평가됩니다(자세한 내용은 하위 섹션 B 참조). 그런 다음 재생산을 위한 개체를 선택하기 위해 적합 비례 선택 방법(룰렛이라고도 알려진 휠 선택)을 사용했는데, 이 방법은 개체의 적합도를 사용하여 선택 확률을 계산하여 후보 개체가 무작위로 선택되지만 인구의 더 큰 비율을 가진 사람들에 대한 편견으로 더 큰 비율을 차지하는 후보자를 무작위로 선정할 수 있습니다. 또한, 한 세대에서 다음 세대로 넘어가면서 솔루션의 품질이 저하되지 않도록 한 세대에서 다음 세대로 넘어가는 과정에서 엘리트주의적 선택 전략도 적용했는데, 이 전략에서는 제한된 수의 최고의 적합도 값을 가진 개인을 다음 세대로 직접 다음 세대로 직접 복사합니다(실험에서는 elitism factor 2%를 사용했습니다.)

번식을 위해 개체가 선택되면, 다음 단계는 알고리즘의 다음 단계는 두 부모의 유전 정보를 결합하여 새로운 자손을 생성하는 크로스오버 과정입니다. 그림 3에서 볼 수 있듯이, 개체의 각 반응 요소(𝑆0 및 𝐺)에 단일 포인트 크로스오버를 사용합니다. 따라서 두 개의 교차점이 무작위로 선택되는데, 하나는 부모의 초기 상태(𝑆0)의 길이를 따라, 다른 하나는 목표 상태(𝐺)의 길이를 따라 선택됩니다. 상태의 길이가 일치하지 않으면 가장 작은 길이를 따라 점이 선택됩니다. 그런 다음 크로스오버 포인트의 양쪽에 있는 부모 상태의 리터럴을 서로 바꿔서 두 개의 다른 자식에 복사합니다(그림 3). Ground Literal을 새 자식에 복사하는 동안 알고리즘은 반복되는 리터럴을 자동으로 제거하고 Γ ⊆ 𝐷𝐵에 따라 Ground Literal의 고유성을 보장합니다. 결국 두 개의 서로 다른 자식이 생성되며, 각 자식은 양쪽 부모의 유전 정보를 가지고 있습니다(그림 3).
그 후 자손은 돌연변이에 노출되어 알고리즘이 국소 최소값에 갇히는 것을 방지하고 인구의 다양성을 유지합니다. 개체의 반응 요소가 Ground Literal 집합으로 표현된다는 점을 고려하면 유전자 뒤집기나 교환과 같은 전통적인 돌연변이 방법을 직접 적용할 수 없습니다. 따라서 초기 상태(𝑆0), 목표 상태(𝐺) 또는 둘 다에서 무작위로 접지 리터럴을 제거하거나 추가하는 돌연변이 절차를 사용했습니다. 돌연변이 확률 𝑀𝑝, 무작위 돌연변이 유형 𝑀𝑡(추가, 제거 또는 추가 & 제거), 무작위 목표 𝑀𝑠(𝑆0, 𝐺 또는 둘 다)가 주어지면 상태 𝑀𝑠에 대해 𝑀𝑡에 따라 변경하면서 확률 𝑀p로 돌연변이가 수행됩니다. 더하기 돌연변이 유형을 수행할 때는 Γ ⊆ 𝐷𝐵에 설정된 규칙에 따라 새로운 접지 리터럴이 무작위로 생성됩니다. 실험에서는 𝑀𝑝 = 20%를 사용했습니다. 크로스오버 과정을 통해 생성된 모든 자손은 돌연변이의 영향을 받을 수도 있고 받지 않을 수도 있는 새로운 집단에 삽입됩니다. 새 개체군의 크기가 최대 개체 수(실험에서는 100개)에 도달하면 현재 개체군이 새 개체군으로 대체되어 새로운 세대가 형성됩니다. 그런 다음 새 세대를 평가하고 주어진 세대 수 동안 전체 프로세스를 반복합니다(그림 2).
B. Fitness Function
유전 알고리즘에서 적합도 함수는 개체를 입력으로 받아 해당 개체에 대한 평가를 나타내는 숫자 값을 반환합니다. 이 방법에서는 퀘스트의 유용성/품질이 원하는 스토리 아크와 얼마나 유사한지에 따라 평가됩니다.
스토리 아크의 개념은 1863년 서사시와 비극에 대한 아리스토텔레스의 아이디어에서 영감을 받은 구스타프 프레이탁이 고전 5막의 서사 구조를 나타내는 간단한 플롯 패턴을 제안한 것으로 거슬러 올라갑니다. 새로운 엔터테인먼트 미디어(예: 영화, 만화책, 비디오 게임)는 짧은 에피소드(예: 80분 영화), 시각적으로 집중적인 담론과 짧은 내러티브 주기(예: 만화 및 그래픽 소설), 대화형 경험(예: 비디오 게임 및 대화형 스토리텔링)에 참여하는 관객을 상대하기 때문에 특별한 요구와 과제를 안고 있습니다. 이러한 경우 극적 구조에 대한 규범적 개념이 매우 유용합니다. 이는 영화와 비디오게임 업계에서 스토리 아크라고 알려진 프레이탁의 피라미드의 단순한 변형이 엄청난 성공을 거둔 이유를 설명할 수 있습니다.
 가장 유명한 스토리 아크는 영화 업계에서 사용하는 3막 구조(그림 4)로, 설정(스토리 시간의 1/4), 대립(스토리 시간의 2/4), 해결(스토리 시간의 1/4 이하)로 나뉩니다. 이 구조에는 세 가지 주목할 만한 전환점이 있습니다:
가장 유명한 스토리 아크는 영화 업계에서 사용하는 3막 구조(그림 4)로, 설정(스토리 시간의 1/4), 대립(스토리 시간의 2/4), 해결(스토리 시간의 1/4 이하)로 나뉩니다. 이 구조에는 세 가지 주목할 만한 전환점이 있습니다:
- 플롯 포인트 1(자극적인 사건)
- 플롯 포인트 2 (주인공이 이길 것인가, 질 것인가, 죽을 것인가 등 결과가 불확실한 감동적인 전환점)
- 위기(클라이맥스, 마지막 극적인 대결, 그리고 그 뒤에 이어지는 결말). 그림 4에서 가로축은 시간을, 세로축은 감정적 긴장을 나타냅니다.
플래너는 HSP2 플래너를 사용. STRIPS와 유사한 형식주의와 완벽하게 호환됩니다. 퀘스트의 줄거리를 획득한 후 스토리 아크는 다음과 같습니다. 플롯을 따라 발생하는 이벤트에 따라 계산됩니다. 예를 들어 이벤트가 있는 플롯 𝑝를 고려합니다:
attack(zombie, anne, home), go(john, johnhome, village), go(john, village, store), get(john, antidote1, store), go(john, store, village), go(john, village, johnhome), cure(john, anne, antidote1, johnhome),
그리고 Ε ⊆ 𝐷𝐵가 연산자의 효과를 정의한다고 가정하면 연산자의 효과를 Ε = { attack:”+”, get:”+”, go:”=”, cure:”-“,…}로 정의하면 플롯 𝑝의 스토리 아크는 다음과 같이 기호 표기법으로 표현할 수 있습니다. parc sym= {+, =, =, +, =, =, -}이고 숫자 표현으로 변환하면 다음과 같습니다. 𝑝𝑎𝑟𝑐 𝑛𝑢𝑚 = {1, 1 ,1, 2, 2, 2, 1}.
플롯의 스토리 아크가 원하는 스토리 아크와 얼마나 유사한지 평가하기 위해 두 아크의 차이를 계산합니다. 그러나 스토리 아크는 서로 다른 시간 척도를 가질 수 있다는 점을 고려하여 먼저 두 호의 스케일을 공통 시간 간격으로 재조정합니다. 실험에서 모든 스토리 아크는 간격 1~10 으로 스케일링합니다:
예를 들어, 3막 스토리 아크 𝑣𝑎𝑟𝑐 𝑛𝑢𝑚 = {1, 2, 3, 2}는 𝑣𝑎𝑟𝑐 𝑠𝑐𝑎𝑙𝑒𝑑 = {1, 1, 2, 2, 2, 3, 3, 2, 2, 2}로 스케일링됩니다. 같은 방식으로 위에 제시된 예시 𝑝𝑎𝑟𝑐 𝑛𝑢𝑚 = {1, 1, 1, 1, 2, 2, 2, 1}의 플롯은 𝑝𝑎𝑟𝑐 𝑠𝑐𝑎𝑙𝑒𝑑 = {1, 1, 1, 1, 2, 2, 2, 2, 1, 1}로 스케일링됩니다. 두 스토리 아크를 동일한 시간 간격으로 스케일링하면 그 차이를 비교할 수 있습니다(그림 5 참조). 
두 개의 스케일 스토리 아크(𝑑와 𝑝)의 차이를 계산하기 위해 스토리 아크(𝑑와 𝑝)의 차이를 계산하기 위해 평균 제곱 오차를 사용합니다. 그리고 최종 적합도를 판단합니다.
C. Optimizations
인구의 개체를 평가하는 과정은 유전 알고리즘에서 가장 계산 비용이 많이 드는 부분으로, 특히 각 개체의 퀘스트 플롯을 생성하기 위해 플래너를 실행해야 하기 때문입니다. 유전 알고리즘은 당연히 오프라인 프로세스이지만, 우리 상황에서는 빠른 응답이 중요하기 때문에 사용자가 게임에서 다양한 파라미터나 수정을 시도할 수 있도록 하기 위해서는 빠른 응답이 중요합니다. 따라서 다음과 같은 두 가지 최적화를 구현했습니다: 병렬 평가와 캐시된 플롯.
각 개인이 독립적인 계획 문제를 나타낸다는 점을 고려할 때, 우리는 멀티코어 프로세서를 활용하여 여러 개체를 병렬로 평가할 수 있습니다. 이 최적화를 위해 다음과 같은 스레드 풀을 사용합니다. 이 최적화를 위해 동시 실행을 위해 작업(개별 평가)이 할당되기를 기다리는 여러 스레드를 유지하는 스레드 풀을 사용합니다. 섹션 V에서 설명하겠지만, 스레드를 사용하면 유전 알고리즘의 전반적인 성능이 눈에 띄게 향상됩니다.
유전 알고리즘 인구의 또 다른 특징은 특히 게임 세계가 작을 때 동일하거나 다른 세대에 걸쳐 균등 계획 문제를 가진 개인이 발생한다는 것입니다. 이러한 경우 동일한 계획 문제를 여러 번 해결해야 하므로 시간과 CPU 리소스가 낭비됩니다. 이 프로세스를 최적화하기 위해 이전 계획 문제에서 생성된 플롯을 저장하는 memoization(memoisation라고도 함) 기술을 구현했습니다. 유사한 계획 문제를 풀려고 할 때 캐시된 플롯이 검색되어 다시 활용됩니다. 캐시는 해시 테이블 구조를 사용하여 키(계획 문제의 초기 상태 및 목표 상태에 따라 계산된)를 값(플롯)에 효율적으로 매핑합니다.
IV. Application
우리의 방법을 테스트하고 검증하기 위해, 우리는 이전 프로젝트에서 개발한 2D RPG를 적용했습니다.(그림 6)  여기서 우리는 제안한 아키텍처를 통합하여 유전 알고리즘에 의해 생성된 퀘스트를 사용했습니다. 이 게임은 좀비 서바이벌 장르에 해당합니다. 좀비 전염병이 지배하는 세상에 살고 있는 한 가족의 이야기를 담고 있습니다. 게임 세계는 15가지의 다른 장소로 구성됩니다: 마을, 숲, 병원, 상점, 주인공의 집, 이웃집, 동쪽, 서쪽, 중앙 지역을 포함하는 섬, 동쪽, 서쪽, 중앙 지역을 동일하게 포함하는 산 지역, 마을과 섬을 연결하는 다리, 섬과 산 지역을 연결하는 또 다른 다리. 세계는 7명의 캐릭터가 거주합니다: 용감한 남편 존(플레이어가 조종), 앤(존의 아내), 매기(존의 딸), 릭(상점 직원), 밥(의사), 매트(나무꾼), 로빈(생존 전문가). 잠긴 문을 여는 열쇠, 감염된 캐릭터를 치료하는 해독제, 굶주린 캐릭터를 먹일 식량, 도구 키트와 함께 사용하여 부서진 다리를 고칠 수 있는 나무 더미 등 여러 가지 수집 가능한 아이템이 세계 곳곳에 흩어져 있습니다. 또한 게임 세계에는 다른 캐릭터를 공격하고 감염시킬 수 있는 좀비도 여러 마리 등장합니다.
여기서 우리는 제안한 아키텍처를 통합하여 유전 알고리즘에 의해 생성된 퀘스트를 사용했습니다. 이 게임은 좀비 서바이벌 장르에 해당합니다. 좀비 전염병이 지배하는 세상에 살고 있는 한 가족의 이야기를 담고 있습니다. 게임 세계는 15가지의 다른 장소로 구성됩니다: 마을, 숲, 병원, 상점, 주인공의 집, 이웃집, 동쪽, 서쪽, 중앙 지역을 포함하는 섬, 동쪽, 서쪽, 중앙 지역을 동일하게 포함하는 산 지역, 마을과 섬을 연결하는 다리, 섬과 산 지역을 연결하는 또 다른 다리. 세계는 7명의 캐릭터가 거주합니다: 용감한 남편 존(플레이어가 조종), 앤(존의 아내), 매기(존의 딸), 릭(상점 직원), 밥(의사), 매트(나무꾼), 로빈(생존 전문가). 잠긴 문을 여는 열쇠, 감염된 캐릭터를 치료하는 해독제, 굶주린 캐릭터를 먹일 식량, 도구 키트와 함께 사용하여 부서진 다리를 고칠 수 있는 나무 더미 등 여러 가지 수집 가능한 아이템이 세계 곳곳에 흩어져 있습니다. 또한 게임 세계에는 다른 캐릭터를 공격하고 감염시킬 수 있는 좀비도 여러 마리 등장합니다.
게임플레이는 스토리 퀘스트를 중심으로 진행되며, 플레이어는 아이템을 수집하고, 플레이어가 아닌 캐릭터와 상호작용하고, 좀비를 죽이고, 잠긴 문을 열고, 부서진 다리를 고치고, 감염된 캐릭터를 치료하고, 굶주린 캐릭터를 먹이는 등의 역할을 수행해야 합니다. 좀비와 싸우기 위해 플레이어는 탄약이 제한된 총을 가지고 있으며, 플레이어가 탄약 키트를 수집하면 재장전할 수 있습니다. 플레이어가 좀비의 공격을 받으면 플레이어는 일정량의 생명력(즉, 처음에 플레이어에게 부여된 생명력)을 잃게 되며, 이는 의료 키트를 수집할 때만 회복됩니다. 이 게임은 Löve 2D 프레임워크를 사용하여 Lua로 구현되었습니다.
게임의 퀘스트를 생성하기 위해 저희는 퀘스트 생성 방법을 사용했습니다. 유전 알고리즘을 테스트하기 위해 100명의 고정된 개체군 규모를 사용했으며, 알고리즘의 각 실행은 100세대로 구성되었습니다. 실행이 끝나면 가장 우수한 개인의 퀘스트만 게임에 포함되도록 선택했습니다. 모든 실행에서 원하는 스토리 아크는 3막 구조로 사용되었습니다. 게임에는 총 3개의 퀘스트가 생성되었습니다:
Q1 = starve(maggie, home), go(john, johnhome, store), ask(john, rick, food2, store), give(rick, john, food2, store), go(john, store, johnhome), feed(john, maggie, food2, johnhome).
Q2 = attack(zombie, anne, johnhome), go(john, johnhome, neighborhouse), kill(john, zombie2, neighborhouse), get(john, hospitalkey, neighborhouse), go(john, neighborhouse, hospitaldoor), opendoor(john, hospitalkey, hospitaldoor), go(john, hospitaldoor, hospital), ask(john, bob, antidote2, hospital), give(bob, john, antidote2, hospital), go(john, hospital, johnhome), cure(john, anne, antidote2, johnhome).
Q3 = attack(zombie, bob, hospital), go(john, johnhome, forest), kill(john, bigzombie, forest), get(john, wood1, forest), go(john, forest, store), get(john, toolkit, store), go(john, store, villageislandbridge), fixbridge(john, toolkit, wood1, villageislandbridge), go(john, villageislandbridge, islandeast), ask(john, matt, antidote3, islandeast), give(matt, john, antidote3, islandeast), go(john, islandeast, hospital), cure(john, bob, antidote3, hospital).
저희 게임 월드는 더 많은 퀘스트를 지원하지만, 섹션 V에서 설명한 사용자 평가 테스트(튜링 유사 테스트)를 위해 인간 디자이너가 더 자유롭게 퀘스트를 디자인할 수 있도록 3개의 퀘스트만 생성했습니다.
V. Evaluation
제안한 방법으로 생성된 결과를 평가하기 위해 (1) 유전 알고리즘의 성능과 진화 과정을 확인하는 기술 테스트와 (2) 시스템이 자동으로 생성한 퀘스트와 인간 게임 디자이너가 수동으로 생성한 퀘스트를 비교하는 사용자 평가 테스트 두 가지를 수행했습니다.
A. Techinical Evaluation
저희 방법의 기술적 평가는 두 가지 실험으로 이루어졌습니다. 먼저, 유전 알고리즘의 진화 과정을 분석하고 무작위 퀘스트 생성 전략과 비교했습니다. 두 번째 실험에서는 알고리즘의 계산 성능을 평가했습니다.
진화 과정을 평가하기 위해 유전 알고리즘을 25회 실행하여 하나의 퀘스트를 생성했습니다. 이 실험에서는 섹션 IV에서 설명한 게임 세계와 유전 알고리즘의 설정인 인구 규모 100명, 엘리트주의 계수 2%, 단일점 교차(섹션 III (A)에 설명한 프로세스에 따라), 변이 확률 20%, 종료 조건 100세대, 원하는 스토리 아크의 3막 구조를 사용했습니다. 이러한 설정은 예비 실험 과정에서 선택된 것입니다.
무작위 퀘스트 생성 전략과 결과를 비교하기 위해 유전 알고리즘의 무작위 초기 모집단을 생성하는 방법을 사용하는 다른 버전의 시스템을 만들었지만, 진화 전략을 적용하는 대신 각각의 새로운 세대가 새로운 모집단으로 초기화됩니다. 유전 알고리즘에서는 이 과정이 100세대 동안 반복되며, 모집단 규모는 100명으로 설정됩니다(총 10.000개의 무작위 퀘스트를 테스트). 각 세대마다 최고의 무작위 퀘스트가 선택되어 유전 알고리즘의 최고, 평균, 최악의 개체와 비교됩니다.
 그림 7은 이 실험의 결과를 보여줍니다. 알 수 있듯이 유전 알고리즘은 단 몇 세대 만에 무작위 전략을 분명히 극복했습니다. 또한 50세대는 이 문제에 대한 최적의 솔루션(즉, 이 게임 월드 구성과 3막 구조를 원하는 스토리 아크로 사용하는 경우)으로 수렴하는 데 충분한 것으로 입증되었습니다.
그림 7은 이 실험의 결과를 보여줍니다. 알 수 있듯이 유전 알고리즘은 단 몇 세대 만에 무작위 전략을 분명히 극복했습니다. 또한 50세대는 이 문제에 대한 최적의 솔루션(즉, 이 게임 월드 구성과 3막 구조를 원하는 스토리 아크로 사용하는 경우)으로 수렴하는 데 충분한 것으로 입증되었습니다.
섹션 III (C)에 설명된 최적화의 효율성을 포함하여 저희 방법의 계산 성능을 평가하기 위해, 유전 알고리즘의 한 세대 동안 100명의 개체군을 처리하는 데 필요한 평균 시간을 계산했습니다(이전 실험과 동일한 설정 사용).
표 I. (1) 최적화가 없는 기본 버전, (2) 다중 스레드를 사용하는 병렬 버전, (3) 다중 스레드와 캐시된 플롯을 사용하는 최적화된 버전의 세 가지 유전 알고리즘에서 한 세대 동안 100명의 개체군을 처리하는 평균 시간.  (1) 최적화가 없는 버전(기본 버전), (2) 평가 프로세스를 위한 다중 스레드가 있는 최적화된 버전(병렬 버전), (3) 다중 스레드와 캐시된 플롯을 사용하는 완전히 최적화된 버전(최적화 버전)의 세 가지 버전의 알고리즘을 테스트했습니다. 실험을 실행하는 데 사용된 컴퓨터는 인텔 코어 i7 7820HK, 2.9GHZ CPU, 16GB RAM이었습니다.
(1) 최적화가 없는 버전(기본 버전), (2) 평가 프로세스를 위한 다중 스레드가 있는 최적화된 버전(병렬 버전), (3) 다중 스레드와 캐시된 플롯을 사용하는 완전히 최적화된 버전(최적화 버전)의 세 가지 버전의 알고리즘을 테스트했습니다. 실험을 실행하는 데 사용된 컴퓨터는 인텔 코어 i7 7820HK, 2.9GHZ CPU, 16GB RAM이었습니다.
각 버전은 유전 알고리즘을 25회 전체 실행하여 100세대씩 테스트했습니다(각 버전당 총 2,500개의 시간 샘플 생성). 표 1은 테스트 결과를 보여주는데, 최적화된 버전이 기본 버전보다 6배 이상 빠르다는 것을 보여줍니다. 최적화 버전은 여전히 퀘스트 플롯을 생성하는 데 상당한 시간이 필요하지만(50세대 동안 알고리즘을 실행하는 데 평균 3.59분 소요), 솔루션의 품질(무작위 전략으로 생성된 것과 비교)이 처리 시간을 상당히 보상해 줍니다.
B. User Evaluation
저희 시스템에서 자동으로 생성된 퀘스트와 게임 디자인 전문가가 수동으로 생성한 퀘스트를 비교하기 위해, 인간 플레이어가 저희 알고리즘이 생성한 퀘스트와 인간 게임 디자이너가 만든 퀘스트를 구분할 수 있는지 평가하기 위해 간단한 튜링 테스트를 실시했습니다. 이 실험을 위해 10년 이상의 게임 업계 경력을 가진 전문 게임 디자이너에게 새로운 캐릭터, 장소, 아이템, 액션을 자유롭게 추가하되, 이전에 알고리즘이 생성한 기존 퀘스트의 로직과 구조에는 간섭하지 않는 새로운 퀘스트 3개를 디자인해 달라고 요청했습니다. 게임 디자이너가 만든 퀘스트는 다음과 같습니다:
DQ1 = go(john, home, store), ask(rick, john, killvillagezombies), go(john, store, village), kill(john, villagezombies, village), go(john, village, store), thank(rick, john).
DQ2 = getlost(george, forest), go(john, home, forest), kill(john, zombie4, forest), find(john, george, forest), take(john, george, forest, hospital).
DQ3 = attack(zombie, maggie, home), go(john, home, islandeast), kill(john, zombie5, islandeast), get(john, wood2, islandeast), go(john, islandeast, islandmountainbridge), fixbridge(john, toolkit, wood2, islandmountainbridge), go(john, islandmountainbridge, mountainwest), attack(zombie, robin, mountainwest), die(robin, mountainwest), steal(john, robin, antidote4, mountainwest), go(john, mountainwest, home), cure(john, maggie, antidote4, home).,
디자이너의 퀘스트를 게임에 통합한 후, 34명의 학생(남성 28명, 여성 6명, 18~23세)에게 게임을 플레이하고 인간 디자이너가 만든 퀘스트인지 기계가 만든 퀘스트인지에 따라 분류해 달라고 요청했습니다. 실험 전에 피험자들에게 어떤 퀘스트는 알고리즘에 의해, 어떤 퀘스트는 게임 디자이너에 의해 만들어졌다고 설명했지만 각 퀘스트가 몇 개씩 만들어졌는지는 알려주지 않았습니다. 각 퀘스트를 완료한 후에는 게임이 자동으로 일시 정지되고, 피험자에게 해당 퀘스트가 인간 디자이너에 의해 생성된 것인지 아니면 기계에 의해 생성된 것인지 판단하라는 메시지가 표시되었습니다. 모든 참가자는 모든 퀘스트를 완료할 수 있었습니다. 각 세션은 평균 32.4분 동안 진행되었습니다(표준편차 8.3).
204개의 데이터 포인트(34명의 플레이어가 각각 6개의 퀘스트를 평가)로 구성된 전체 테스트 세트에서 “기계” 버전은 총 102건 중 48건, “인간” 버전은 총 102건 중 52건에서 정확하게 식별되어 전체적으로 49.02%의 정확도를 기록했습니다. 이상적인 튜링 테스트는 컴퓨터 버전과 인간 버전을 구분할 수 없는 경우로, 따라서 50%의 정확도를 무작위로 선택하는 것으로 나타납니다. 달성된 정확도(49.02%)와 이상적인 튜링 테스트 값(50%) 사이의 작은 차이는 컴퓨터로 생성된 퀘스트와 사람이 디자인한 퀘스트가 거의 구분되지 않는다는 것을 의미하며, 이는 제안된 퀘스트 생성 방법이 전문 게임 디자이너가 만든 것과 매우 유사한 퀘스트 플롯을 달성할 수 있다는 것을 나타냅니다.
VI. Conclusion remarks
이 논문에서는 새로운 퀘스트 생성 계획과 진화적 검색을 결합한 새로운 퀘스트 생성 전략을 결합한 새로운 퀘스트 생성 방법을 설명했습니다. 일관성 있고 다양한 퀘스트를 생성할 수 있는 구조를 기반으로 일관되고 다양한 퀘스트를 생성할 수 있습니다. 유니티의 방식은 게임 디자이너에게 새로운 새로운 게임 내러티브를 상상하고 제작할 수 있는 방법을 제공합니다. 또한 게임 개발자는 이 기법을 활용하여 다음을 수행할 수 있습니다. 게임의 새로운 퀘스트를 설계하는 과정을 자동화할 수 있습니다, 따라서 개발팀의 업무 과부하를 줄일 수 있습니다. 개발팀의 업무 과부하를 줄일 수 있습니다.
실험 결과, 제안된 방법은 고무적인 결과를 보여주었습니다. 유전 알고리즘은 몇 세대 만에 무작위 퀘스트 생성 전략을 쉽게 극복할 정도로 전반적으로 우수한 진화 진행률을 보였습니다. 또 다른 암시적인 증거는 플레이어가 우리의 방법으로 생성된 퀘스트와 전문 게임 디자이너가 만든 퀘스트를 구별할 수 없었다는 사실에서 찾을 수 있습니다.
성능 측면에서, 우리 방법의 일부 최적화가 이미 구현되었지만 사용자는 여전히 결과를 시각화하기 위해 몇 분을 기다려야 합니다(섹션 V (A)에 설명된 대로). 따라서 다음 연구 목표 중 하나는 계획 알고리즘을 더 빠른 방법(예: 계층적 작업 네트워크)으로 대체하거나 클라우드 컴퓨팅 아키텍처를 구현하는 등 저희 방법의 전반적인 성능을 개선할 수 있는 대안을 찾는 것입니다.
성능 향상을 위한 대안을 모색하는 과정에서 추구해야 할 또 다른 연구 목표로, 분기 스토리라인이 있는 내러티브 생성을 지원하도록 제안된 방법을 확장할 계획입니다. 최고의 개체의 최종 상태를 유전 알고리즘의 새로운 실행을 위한 초기 상태로 사용하여 대체 경로를 생성할 수 있습니다. 이러한 형태의 분기 스토리라인은 게임 디자이너에게 기존 퀘스트를 새로운 형태의 인터랙티브 스토리텔링으로 확장할 수 있는 새로운 방법을 제공할 수 있습니다.
