행동 복제를 통한 다양한 플레이 스타일 중심의 에이전트 생성
2023월 10월 06일 제19회 AAAI 인공지능 및 대화형 디지털 엔터테인먼트 컨퍼런스
Creating Diverse Play-Style-Centric Agents through Behavioural Cloning | Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment Creating Diverse Play-Style-Centric Agents through Behavioural Cloning 행동 복제(Behavioural Cloning)를 통한 다양한 플레이 스타일 중심의 에이전트 생성
개요
- 다양한 수준의 다양한 플레이스타일을 포괄하는 에이전트를 만든다
- 비지도 플레이 스타일 식별과 정책 학습 기술을 결합했다
- PCPG(Play-style-Centric Policy Generation: 플레이 스타일 중심 정책 생성) 파이프라인을 제안
소개
- 인간 플레이어가 보여주는 다양한 플레이 스타일을 표현하고 싶음
- 기존의 행동을 복제하는 것을 목표로 하는 대안적 접근 방식은 인간과 유사한 행동을 생성하는 데 효과적
- 유사한 행동 정책을 학습할 수 있는 특성 집합을 설계하거나 자동으로 식별해야 한다
- 원하는 플레이 스타일을 설명하는 관련 특징을 세분화한 다음, 이러한 특징을 행동에 매핑하는 정책을 학습
- 또는 클러스터링이나 차원 재연결 같은 기술을 사용하여 데이터에서 관련 플레이 스타일 특징을 자동으로 추출한 다음 이를 통해 정책을 학습
- PCPG 파이프라인
- 비지도 플레이 스타일 식별과 정책 학습 기법의 조합
- 비지도 식별 프로세스를 통해 식별 가능한 행동에 따라 시연을 하위 집합으로 나눈다
- 정책 학습 방법을 적용하여 특정 플레이 스타일을 모방할 수 있는 에이전트를 훈련
- 목표: 게임 내 다양한 플레이 스타일을 다양한 수준의 숙련도로 정확하게 표현
관련 작업
- 보상 중심
- Reinforcement learning
- Reward Function 보상함수
- 에이전트가 특정 행동을 취할 때 얼마나 잘햇는지 평가하여 숫자로된 보상 반환
- Reward Shaping 보상 구조 수정
- 기존 보상함수에 추가적인 보상을 더하는 과정. 특정행동을 하거나 스타일을 따를 때 보상을 주어 구체적인 스타일을 따르도록 함.
- 각 행동에 얼마나 보상을 주어야하는지 결정할 때 전문 지식이 필요해서 설계가 까다로움.
- 데이터 중심
- Imitation Learning
- Supervised Learning 지도학습
- 모방학습에서 기본적으로 사용하는 학습 방식. 사람이 하는 행동을 학습 데이터로 활용
- Expert Demonstrations 전문가 시범
- 전문가의 시범을 보고 이를 바탕으로 학습
- State and Action 상태와 행동
- 환경의 상태를 보고 그 상태에서 어떤 행동을 취해야하는지 학습
- 복잡한 행동을 학습 가능하고 실제 환경에서 활용하기 좋다
- 한계
- 데이터를 뛰어넘어서까지 행동할 수 없음. 시범을 보이지 않은 항목에 대해서는 오류 발생 (Distributional Shift 분포이동)
- 대규모의 데이터가 필요
- DAGGER 알고리즘
- 에이전트가 잘못된 행동을 할 때, 전문가가 다시 피드백
- Unsupervised Clustering 비지도 학습 클러스터링
- 플레이어가 어떤 스타일로 게임을 진행하는지 알지 못하는 상태에서, 유사한 행동 패턴을 가진 그룹으로 데이터를 자동으로 묶어내는 비지도 학습 기법
- Clustering
- 비슷한 데이터를 하나의 그룹으로 묶는 방법
- 비지도학습에서는 클러스터링 과정에서 데이터를 미리 라벨링 하지 않고, 데이터 내의 패턴을 찾아 자동으로 그룹을 나눔
- 게임 플레이 경험에 존재하는 시간적 측면이나 시간 경과에 따라 또는 레벨에 따라 플레이 스타일이 어떻게 변화하는지를 반영하지 못함
Behavioural Cloning
모방 학습의 한 형태로, 전문가를 활용하여 원하는 행동을 시연한다.
- state ∈ Trajectory
- state: 에이전트가 현재 처한 환경의 정보
- Trajectory: 에이전트가 특정 시점부터 목표에 도달할 때까지의 상태와 행동의 연속적인 기록
- 특정 시점에서 에이전트가 처한 상태 sss는 궤적이라는 일련의 상태 변화 중 하나
- Trajectory에서 에이전트가 겪는 각 상태를 나타내는 시퀀스가 있다
- (Dataset) ={X0,X1,…,Xh}
- Dataset: 전문가가 시범을 보이며 생성한 상태-행동 묶음
- Xs: 각 Trajectory
- 즉 모든 Trajectory를 묶어 데이터셋을 생성
- policy−π: 에이전트의 정책(주어진 상태에서 어떤 행동을 취할지를 결정)
정책을 뽑아내는 식으로는…
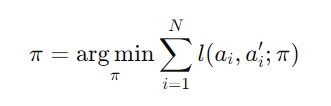
- arg min
- 손실을 최소화하는 정책π을 찾겠다
- ∑
- i는 각 데이터 포인트
- N개의 데이터 포인트에 대해 학습하는 과정
- l(ai,ai′;π)
- 손실함수 loss function
- 에이전트가 예측한 행동 (a’i)과 전문가가 실제로 취한 행동(ai)간의 차이 측정
- 예측이 행동과 다를수록 손실이 커진다
방법론
- Play-Style-Centric Policy Generation (PCPG)
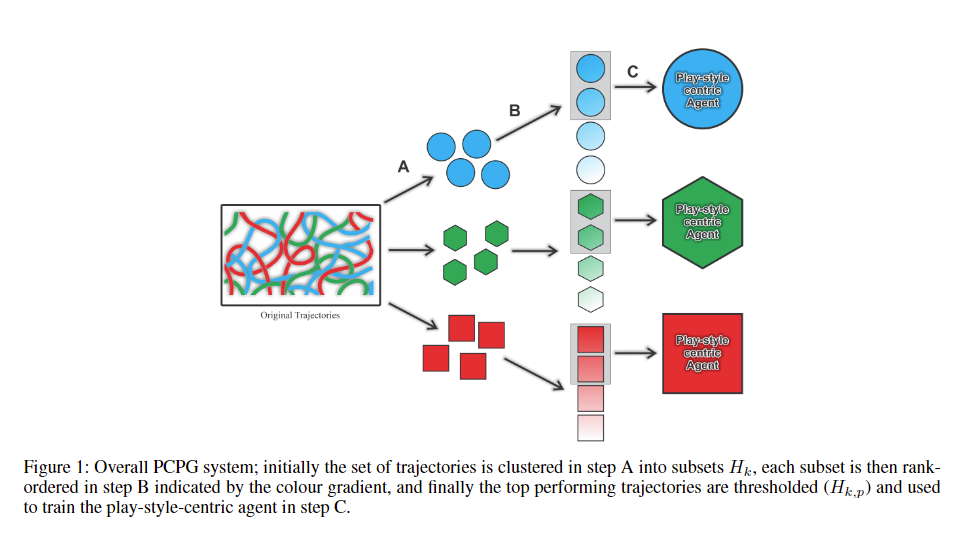
A단계: 클러스터링 기법을 사용하여 관찰 데이터 = 다차원 Trajectory 데이터를 식별 가능한 다양한 플레이 스타일에 따라 분리 B단계: 특정 기술 범위에 따라 분리된 관찰 데이터를 필터링할 수 있도록 순위 함수를 기반으로 궤적의 순서를 매김 C단계: 생성된 각 하위 집합에 대해 개별 BC 모델을 훈련
각 선택 항목에는 특정 행동과 관련된 데이터가 포함되어 있으므로 ‘플레이 스타일 중심 정책 생성’이라고 명명
Trajectory Clustering (A단계)
플레이어의 다양한 스타일을 식별하기 위해, 유사한 행동 패턴을 가진 궤적을 클러스터로 묶는 단계
- 궤적을 더 작은 차원으로 변환(차원 축소)한 후
- LSTM 오토인코더라는 신경망을 사용
- LSTM(장단기 기억 네트워크): 시간 흐름에 따른 데이터를 처리하는 신경망 플레이어가 시간에 따라 어떻게 행동했는지를 추적 가능하다
- 오토인코더: 데이터를 입력받아 중요한 특징만 남기고 불필요한 정보를 압축하는 신경망
- 각 궤적을 특정 잠재 공간(latent space)에 매핑 (잠재 공간은 궤적을 축약한 표현)
- 클러스터링 알고리즘을 사용하여 유사한 Trajectory들을 하나의 그룹으로 묶음
인코더가 궤적의 중요한 특징을 남기고, 불필요한 정보는 제거하는 과정의 수식
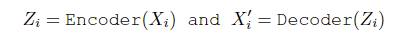
- Xi: 원래의 Trajectory
- Encoder: = LSTM 인코더, Trajectory를 축약된 표현으로 변환하는 신경망
- Zi: latent space 잠재공간 차원 축소(dimensionality reduction technique)를 이용하여 실제 관찰 공간(observation space)을 관찰 대상들을 잘 설명할 수 있는 잠재 공간(latent space)으로 축소
- Decoder: 잠재 공간의 데이터를 다시 원래 Trajectory로 복원
- X’i: 재구성된 Trajectory
Trajectory Ranking (B단계)
성능에 순위를 매기는 단계. 각 클러스터 안에서 Trajectory의 성능(기술 수준)에 따라 순위를 매긴다. = 즉, Trajectory를 상위 플레이어와 하위 플레이어로 구분하는 단계.
- 각 Trajectory를 Ranking Function을 사용하여 성능 기준으로 정렬
- Performance: Trajectory의 길이(ex. 얼마나 빨리 도달했는가?)를 사용하여 순위를 매긴다. 짧을 수록 더 나은 성과를 뜻함
- 상위 p%의 Trajectory만 선택하여 최상위 기술 수준을 학습하는 에이전트를 훈련
궤적의 성능을 평가하는데, 궤적이 짧고 목표 상태에 도달할수록 더 높은 성능을 부여하는 수식
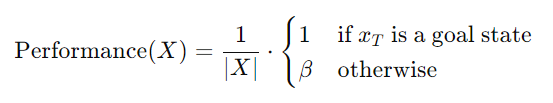
- Performance(X): 각 Trajectory X의 성능
- ∣X∣: Trajectory의 길이. 짧을수록 목표 달성을 빨리 한 것 즉 1/∣X∣ 는 짧을수록 값이 높아지게 만드는 역할
- xT: 궤적의 마지막 상태.
- β: 목표 상태에 도달하지 못했을 때 성능을 벌점으로 조정하는 상수
Policy Learning (C단계)
각 클러스터에서 추출된 Trajectory를 바탕으로, 해당 플레이 스타일을 모방하는 정책(Policy)을 학습하는 단계
- 행동 복제(Behavioural Cloning): 지도 학습을 사용하여, 상태-행동 쌍을 학습
- 주어진 상태에서 행동을 예측하고, 그 예측된 행동과 실제 행동 사이의 차이를 최소화하려 함
- 각 클러스터에 맞는 스타일 중심 정책을 학습
예측한 행동과 실제 행동 사이의 차이를 줄이는 방향으로 정책을 수정하는 수식
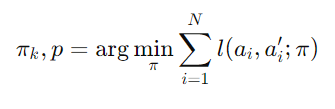
- πk,p: 특정 스타일 k와 성능 수준 p에 맞춘 정책
- ∑in=1: N개의 Trajectory에 대해 반복적으로 학습을 수행
- l(ai,ai′;π): 손실함수(전문가와의 행동 차이가 클수록 손실 값이 커짐)
- arg min π: 손실함수의 값을 최소화하는 정책 π 찾기
실험
- 검증을 위해 세 가지 데이터셋에서 모델을 평가
- 두개의 인공 데이터셋(synthetic datasets)
- 하나의 자연 데이터셋(natural datasets)
GridWorld
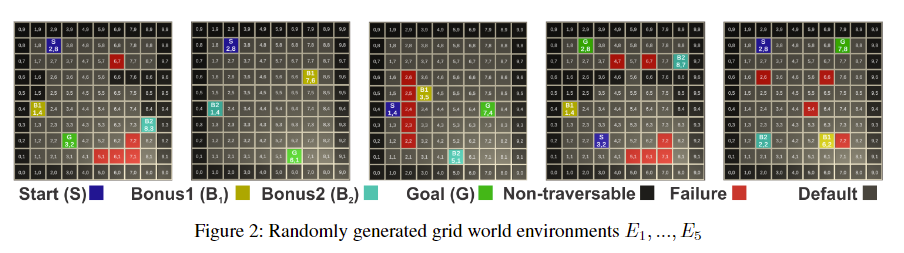
랜덤하게 생성된 GridWorld 환경
- GridWorld 데이터셋
- 격자형 환경에서 플레이어가 목표지점을 찾아가는 게임
- 두 개의 선택적(옵션) 목표를 추가. 즉 추가 목표를 달성할 수 있음
- 플레이어가 어떤 스타일로 게임을 했는지 명확하기에 모델이 얼마나 잘 학습했는지 정확하게 평가가 가능하다

다양한 플레이 스타일을 정의하고, 각 스타일에 따른 보상 구조를 설명
- G: 목표
- B1, B2: 보상 추가 지점
Preference-Based Trajectory Generation (PBTG) 보상 기반 Trajectory 생성 알고리즘
procedure PBTG(Environment E) # 주어진 환경 E에서 동작한다
보상함수 R 정의
Trajectories 집합 D를 초기화
for all 보상함수 R do
Q-learning을 사용해 주어진 보상 함수에 대해 최적의 정책 πr을 학습
for Trajectory의 개수만큼 do
# 플레이 스타일 안에서 약간의 다양성을 만들기 위해
학습한 최적 정책을 약간 변형하여 새로운 정책 πrn을 생성
Generate X(n,r) from πrn 그리고 D에 추가
end for
end for
end procedure
MiniDungeons
- MiniDungeons 데이터셋
- 2D 던전 탐험 게임. 여러 레벨이 존재한다.
- 비디오 게임 연구에서 많이 사용되는 표준 데이터셋
- 인간 같은 행동을 바탕으로 만들어진 데이터. 2D 레벨에서 다양한 행동을 보이는 플레이어들의 데이터를 포함한다.
- 인간 같은 행동을 얼마나 잘 학습하고 재현하는지 평가가 가능하다
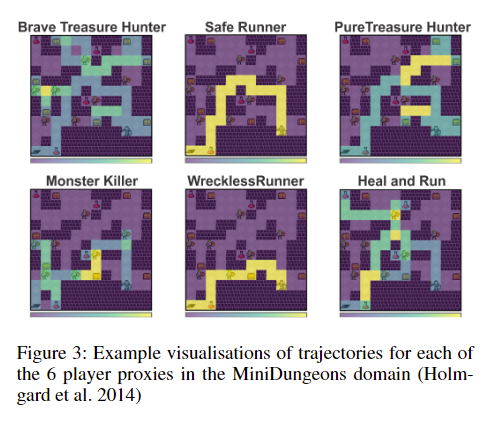
미니던전에서의 플레이어의 행동 스타일
- Safe Runner: 안전하게 이동하는 플레이어. 몬스터를 피하고 던전을 빠르게 완료하는 것이 목표
- Wreckless Runner: 무모한 플레이어. 던전을 가능한 빨리 완료하려고 하지만, 몬스터를 피하지 않고 진행. 가능한 한 빠르게 진행하려는 점은 같지만, 안전을 고려하지 않는다
- Brave Treasure Hunter: 용감한 보물 사냥꾼. 적이 있는 구역이라도 보물을 찾기 위해 돌진. 몬스터가 지키고 있는 보물을 찾는 것이 목표
- Pure Treasure Hunter: 순수한 보물 사냥꾼. 몬스터가 없는 구역에서만 안전하게 보물을 수집. 즉, 적이 없는 곳에서만 보물을 찾는 것이 목표
- Safety-First: 안전 우선 플레이어. 몬스터와의 전투를 피하면서, 보물과 포션만 수집. 전투는 최소화
- Monster Killer: 몬스터 사냥꾼. 최대한 많은 몬스터를 처치하는 것이 목표. 던전클리어보다 몬스터 처치가 우선
Mario
- Super Mario Bros 데이터셋
- 라벨이 없는(unlabelled) 데이터 = 플레이어가 어떤 스타일로 게임을 했는지 미리 정의된 정답이 없다
- 자연 데이터셋(natural domain)
- 모델이 실제 환경에서 얼마나 잘 작동하는지를 평가가 가능하다
슈퍼 마리오 브라더스의 11개 레벨에 걸친 74개의 플레이로 구성함. 상태를 (j,k,r,c,d,e)로 주어진 튜플로 정의
- j: 점프 횟수
- k: 죽인 적의 수
- r: 플레이어가 달리기 시작한 횟수
- c: 수집한 코인의 갯수
- d: 죽은 횟수
- e: 고유 액션 인코딩
훈련
Trajectory Clustering
- 사전 학습된 비지도 LSTM(Long Short-Term Memory 장단기 메모리) 클러스터링 모델을 사용
- 시계열 데이터를 처리하는 데 효과적인 신경망
- 셀과 세개의 게이트로 구성되어 있음
- 입력 게이트
- 망각 게이트와 동일한 시스템을 사용하여 현재 셀 상태에 저장할 새 정보를 결정
- 출력 게이트
- 이전 및 현재 상태를 고려하여 정보에 0~1 사이의 값을 할당하여 현재 셀 상태에서 어떤 정보를 출력할지 제어
- 망각 게이트
- 이전 상태와 현재 입력을 0과 1 사이의 값으로 매핑하여 이전 상태에서 삭제할 정보를 결정
- 셀은 임의의 시간 간격에 걸쳐 값을 기억
- 세 개의 게이트는 셀로 들어오고 나가는 정보의 흐름을 조절
Play-style-centric Model 플레이스타일 중심 모델 구조
- 3개의 완전 연결 레이어(Fully Connected Layers)로 구성되어있음
- 각 레이어에는 5개의 노드가 존재
- 타임스텝: 시간 흐름에 따른 각 상태. (ex. 에이전트가 이동할 때 매 순간마다 상태가 변함) 단일 타임스텝: 하나의 순간에서의 상태. 이 상태에서 에이전트는 어떤 행동을 해야할지 결정함
- 입력: 현재 상태 출력: 어떤 행동을 할 지 예측
- 타임스텝 길이 (복잡한 환경을 처리할 때 더 많은 입력값을 필요로 함)
- GridWorld: 4 (한번에 4개의 값을 보고 어떤 행동을 취할지 결정)
- MiniDungeons: 15
- Mario: 6
실험 설정
- 4개의 시드를 사용하여 5개의 GridWorld, MiniDungeons, Mario 도메인에서 진행
- 각 실험의 평균 정확도를 기록
- 2000번의 학습을 통해 최적의 정책을 학습
초기 데이터셋
각 플레이어가 목표 지점까지 이동하는 다양한 행동 패턴 포함
- GridWorld: 4000개의 Trajectory 사용
- MiniDungeons: 780개의 Trajectory 사용
- Mario: 74개의 Trajectory 사용
Ranking Mertic 순위 지표
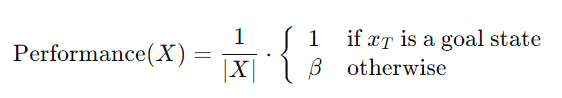
- Equation 3
- 성능 평가 수식. 최종상태가 목표상태에 도달했는지를 기준으로 성능을 평가
- Performance(X): Trajectory X의 성능을 나타내는 값
- ∣X∣: Trajectory의 길이. (ex. 에이전트가 목표지점까지 이동하면서 몇 번의 상태 변화를 겪었는지)
- 1/∣X∣: 짧을 수록 성능이 더 좋게(높게) 평가됨
- 목표도달 성공: 최종 상태xT 목표에 도달했을 경우 성능을 1로 설정
- 목표도달 실패: β (패널티 상수): 궤적이 목표 상태에 도달하지 못했을 경우 벌점을 준다
- β=0.5 점수가 절반으로 줄어든다
- 이 연구에서는 β=0.1을 사용 (매우 큰 페널티라는 뜻)
실험에서는 상위 퍼센트의 궤적만 사용해 훈련하는 방식을 사용
- p=1p: 전체 궤적을 사용해 훈련하는 경우.
- p=0.1p: 상위 1%의 궤적만 사용하여 훈련하는 경우.
평가
모델이 현재 상태에서 다음 상태로 넘어가기 위해 올바른 행동을 예측할 수 있느냐를 평가.
- Autoregressive 자동회귀 방식
- 이전 예측값에 따라 다음 상태를 예측하는 방식
- 모델이 매번 이전 상태를 기반으로 다음 상태를 예측
- 오차 축적 문제발생: . 한 번 예측이 잘못되면 그 잘못된 예측을 계속 기반으로 하여 오류가 점점 더 커짐
- Ground Truth State 입력으로 해결
- 실제 상태(Ground Truth State)를 모델에 입력으로 제공
- 모델이 이전에 예측한 값을 사용하지 않음
- 매번 실제 상태 데이터를 사용해서 다음 행동을 예측
C단계를 사용하지 않은 기준 모델과의 비교
- 랜덤 기준 모델(Random Baseline)와 비교
- 모델이 임의의 행동을 선택하는 모델
- 단, 마스킹을 사용하여 특정 상태에서는 Invalid한 행동은 막아서 성능을 높임
- ex. 차단된 경로가 있다면 해당 경로 외의 경로를 선택
결과
PCPG 모델은…
- 정확하게 플레이 스타일을 재현
- 모든 도메인에서 좋은 성능을 기록
행동 및 기술 기반 다양성
- 다양한 행동 패턴을 학습하는 데 성공함
- 얼마나 잘 플레이하는지(기술 수준)도 모델이 학습할 수 있었음
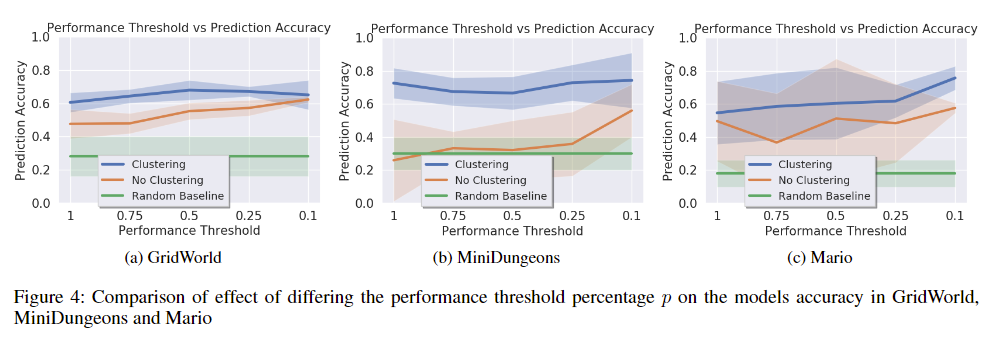
클러스터링이 모델에 미치는 성능 영향
- 플레이어의 스타일을 더 세분화하고 그 스타일에 맞는 행동을 학습할 수 있었기 때문에 더 나은 성능을 발휘했다고 주장
- 클러스터링 임계값(Threshold)에 따른 성능 변화가 존재했음 (상위 p%로만 학습시킴)
한계
- 모델의 예측 정확도가 노이즈로 인해 떨어진다. 에러가 누적되면서 결과의 정확도가 낮아질 수 있음
- 임계값 설정을 통해 성능을 조절했지만 어떤 임계값이 가장 적합한지 최적화 과정이 부족했음
발전내용
- 더 복잡한 도메인으로 실험
- 다양한 행동 패턴의 확장
- 노이즈 처리 기법 개선
- 강화 학습과의 결합
결론
- PCPG 모델로 다양한 플레이 스타일을 성공적으로 학습하고 재현할 수 있음
- 플레이어의 행동을 세분화해서 학습
- 정확하고 전문화된 행동 예측이 가능
- 클러스터링은 중요하다…
- 모델 성능을 향상
- 특정 플레이 스타일에 더 전문화된 학습이 가능
