인공어의 음성합성AI
2022년 11월 12일 CEDEC KYUSHU 2022 발표
https://cedil.cesa.or.jp/cedil_sessions/view/2685 CEDEC KYUSHU 2022 computer entertainmet developers conference
意味が分からないからこそ、リアル ~「架空言語」音声合成による、没入感の高いボイス付きコンテンツの実現~
株式会社スクウェア・エニックス AI部 AIリサーチャー 森 友亮
의미를 모르기 때문에 리얼 ‘인공어’ 음성 합성을 통한 몰입감 높은 음성 콘텐츠 구현 주식회사 스퀘어 에닉스 AI부 AI 연구원 모리 유우리키
사진촬영, SNS 게재 가능
인공어란?
- 실제로 존재하지 않는 가상의 언어
- ex. 몬스터헌터의 언어, 톨킨의 엘프어…
텍스트 음성합성이란?
- 텍스트를 음성파일로 만들어내는 기술 (ex. TTS: Text-To-Speech)
- 하지만 여전히 엔터테인먼트 제품에 사용할만한 품질이 못된다
아이디어의 시작
- 왜 우리는 합성으로 만들어진 음성에서 미세한 위화감을 느낄까?
- 들리는 언어가 모국어이기 때문이 아닐까?
- -> 모국어를 사용하지 않는 접근방법을 사용해보면 어떨까?
- 머신러닝에는 학습단계와 추론 단계가 있는데 여기서 사용할 것은 TTS의 추론 단계의 아이디어
- 학습: 데이터에서 룰을 배운다
- 추론: 학습한 룰을 사용한다
기존의 텍스트 음성합성 방법
TTS의 3가지 스텝
- Text Analysis: 입력한 텍스트에서 텍스트의 언어학적 특징을 추출
- Acoustic Model: 텍스트 특징을 음성 특징으로 변환
- Vocoder: 음성 특징에서 음성을 생성
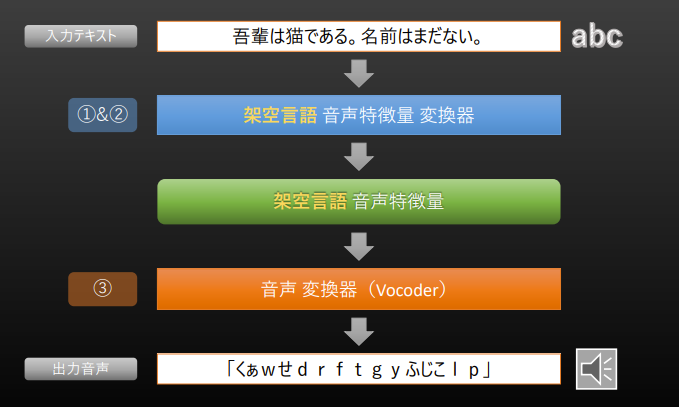
인공어에 대한 음성합성 기술 아이디어
- 1&2단계에서 음성 특징을 얻을 때, 일부러 입력 문자열의 언어와 다른 언어에 대응하는 모델로 처리 (ex. 일본어를 영어로)
- 인공어의 음성특징을 추출
- 인공어 음성특징을 사용하여 언어합성을 하고 음성을 생성
인공어 음성 특징 변환기
- 위 그림의 1단계/2단계에 해당하는 단계에서 사용하는 변환기
- 머신러닝 모델에서 텍스트를 다룰 때, 먼저 텍스트를 컴퓨터가 처리할 수 있는 형식으로 변환한다.
- 이 변환에서 일본어의 언어 의존성 부분을 다른 언어의 것으로 대체한다.
텍스트 토큰화
텍스트를 단어, 음절, 문자 또는 심지어 음소(발음 단위)로 나누는 것
- GitHub - r9y9/pyopenjtalk: Python wrapper for OpenJTalk 를 활용했다고 함
G2P: 발음모델
음소 시퀀스를 단어 시퀀스로 변경하기 위해 참고하는 모델 음성 정보와 텍스트 정보를 상호 변환 ex. 살구(살구), 볼살(볼쌀), 살의(살릐) : ‘살’ 은 동일한 문자로 표기되지만 모두 다른 발음 즉 이러한 발음변이 규칙을 찾고 예외처리를 적용하는 모델
일본어 음소 토큰화의 예시 음소: 하나의 소리로 인식되며 단어의 뜻을 구별해주는 말소리의 최소 단위
In [1]: import pyopenjtalk
In [2]: pyopenjtalk.g2p("こんにちは")
Out[2]: 'k o N n i ch i w a'
In [3]: pyopenjtalk.g2p("こんにちは", kana=True)
Out[3]: 'コンニチワ'
벡터 변환
토큰화 이후, 토큰화한 텍스트를 컴퓨터가 이해할 수 있는 형태로 변환 각 토큰을 고유한 벡터(숫자 배열)로 변환한다 벡터?: 단어들 간의 관계(유사성 등)를 반영할 수 있도록 훈련된 값
이 모델에서는 78개의 토큰으로 변환하고, 각 토큰을 512차원 벡터로 변환한다.
- 텍스트의 토큰화 처리 부분의 핵심
- 이 영어 모델 예시에서는 먼저 텍스트를 78개의 토큰으로 변환한다.
- 입력한 텍스트를 토큰화할 때 78종에 대응할 수 있다면, 그 이후의 처리는 문제없이 처리할 수 있음
Tacotron2( (enc): encoder( # 78 입력으로 사용할 총 토큰 수(알파벳 문자나 음소 등) # 512: 각 토큰이 임베딩된 벡터의 크기 = 78개의 토큰을 각각 512차원의 벡터로 변환하겠다는 뜻 #패딩: 길이가 다른 시퀀스를 처리할 때 고정된 길이로 맞추기 위해 추가하는 특별한 값 (embed): Embedding(78, 512, padding_idx=0) (convs): ModuleList( (0): Sequential( # 1차원 컨볼루션 레이어 층. 입력 채널과 출력 채널이 둘 다 512 (0): Conv1d(512, 512, kernel_size(5,), stride(1,), padding=(2,), bias=False) # Batch Normalization 층 (1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) # 활성화 함수 (2): ReLU() # 드롭아웃 레이어. 과적합(overfitting)방지를 위해 0.5(절반)의 뉴런을 무작위로 드롭 (3): Dropout(p=0.5, inplace=False) ) (...)
[!컨볼루션 레이어] 입력 데이터(예: 이미지나 시퀀스)를 작은 필터(filter), 또는 커널(kernel)을 사용해 처리한다. 필터는 데이터의 일정 부분을 스캔하면서 특정 패턴(ex. 모서리, 색상 패턴) 을 찾고 그 값을 계산해서 결과(feature map)를 만들어낸다 즉, 컨볼루션 레이어는 입력 데이터의 특징(feature)을 추출해낸다
- 커널 크기(kernel size): 필터의 크기
- 패딩(padding): 입력 데이터의 가장자리에 인위적으로 값(주로 0)을 추가. 이를 통해 입력과 출력의 크기를 유지하거나 경계 정보 손실을 방지.
- 스트라이드(stride): 필터가 입력을 이동하는 간격. 1이면 필터가 한 칸씩 이동하고, 2이면 두 칸씩 이동
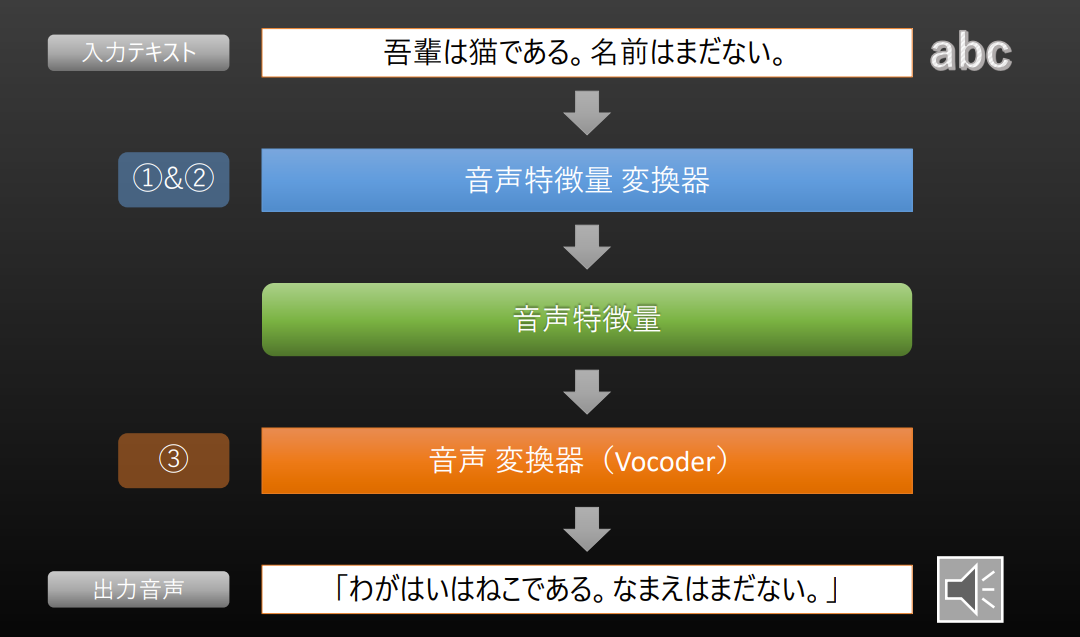
일본어 텍스트 → 영어풍 인공어음성으로 변경
- 일본어 입력 텍스트를 영어용 음성특징 변환기를 통해 처리
- 얻어진 음성 특징은 영어에 가까운 음성 특징이 될 것으로 기대
이 음성 특징을 영어용 음성 변환기에 넣어 합성
- 일본어도, 영어도 아닌 언어의 음성이 나온다
- 누구에게나 낯선 언어이기 때문에 ‘미세한 위화감’이 없다
- ‘원래부터 그런 언어였겠지’라는 생각이 든다
- 토큰화 조건을 충족한다면 어떤 언어로든 가능함
인공어 생성 조건
- 텍스트를 토큰으로 분할해야만 하는데, 이 토큰의 분할에는 언어 의존성이 있다
- 영어 음성 합성 모델의 경우 영어 텍스트를 토큰(음소, 문자 등)으로 변환하는 처리가 필요했다
- 즉, 영어가 아닌 요소(OOV)에 대한 처리도 정의되어 있다면 가상의 언어 음성 생성에 사용할 수 있다
- Out Of Vocabulary: 학습한 단어 집합에 존재하지 않는 단어들이 생기는 상황
인공어음성의 장점
- 이 기술에서는 인위적으로 언어를 만들 필요가 없다
- 언어에 대한 전문 지식이 없어도 일본어 문장을 입력하는 것만으로 게임 게임 세계에 실제로 존재하는 듯한 음성을 생성할 수 있었다
- 문자열 길이와 동일한 길이의 음성을 만들 수 있다
- 기존 방식으로는 자막과 음성 길이에 차이가 있어 언어에 따라 의도한 ‘차이’를 표현하지 못하는 경우가 있었음(AAA 타이틀에서 두드러짐)
- 익숙하지 않은 언어이기 때문에 위화감이 적다
- 동적 생성이 가능하다
- 플레이 언어에 따라 가상의 음성 내용이 달라진다
- 일본어 플레이에 의한 가상의 언어 A
- 영어 플레이에 의한 가상의 언어 A
- 여러 가상의 언어톤이 지원된다 (유럽식, 아시아식, 아프리카식)
- 게임 속 가상 세계에서 일본어를 사용한다던가, 전세계적으로 같은 단어를 사용한다던가 하는 위화감 해소가 가능하다
- 플레이어의 입력에 따라 게임 내용이 동적으로 변화하는 경우에도, 모든 음성을 녹음하지 않아도 된다.
마무리
- 언어에 대한 전문 지식이 없어도 게임 세계에 실제로 존재하는 것처럼 가상의 언어 음성을 생성할 수 있는 기술
- 게임 내용이 동적으로 변화하는 콘텐츠도 위화감 없는 합성음성을 통해 동적으로 풀보이스를 구현할 수 있습니다.
- ‘소설 속 세계에서 사용되는 언어’를 실제로 들을 수 있다는 완전히 새로운 경험을 제공할 수 있다.
- ‘의미를 알 수 없는 합성음성’을 착안한 것은 엔터테인먼트 업계에서나 가능한 일이다.
